Knowledge(graph) is Power!

Aaron Ross
Software Engineer / Web Developer @ EyeCue LabRecently I've been trying to get myself organized, and one thing that has been recommended to me time and again is the bullet journal method for tracking my daily tasks. Usually though, I can actually keep track of things for a day at a time and I can be rather productive when focused on tasks. My issue lies in connecting things over time:
I needed a something that could help me keep track not just of today's tasks, but help me connect yesterday's tasks with tomorrow's.
In steps logseq
Graph Databases#
We are going to take a brief detour to talk about Graph Databases. While most people might be familiar with a standard database that structures data into table like structures where each row corresponds to a single entry and each column corresponds to a property, like name, email, or last_signed_in. From here the world opens up by doing things like joining tables together and then making advanced selections against the results. This is often called a Relational Database and as the name implies they are a really good strategy for storing relational data structures.
While the most common it isn't the only way to structure your relational data. With a graph database the data isn't really the first class citizen, the relationship is. This is borne out in three fundamental terms when thinking about graph data where instead of thinking about records, tables and their relations graph databases track properties, nodes and their edges.
- properties: are comparable to table columns in a relational database and are individual pieces of information associated to nodes
- nodes: are analogous to records but unlike a table record in a relational database a node can have any properties associated that we want
- edges: are the relationships, or connections, between nodes and where things really get interesting.
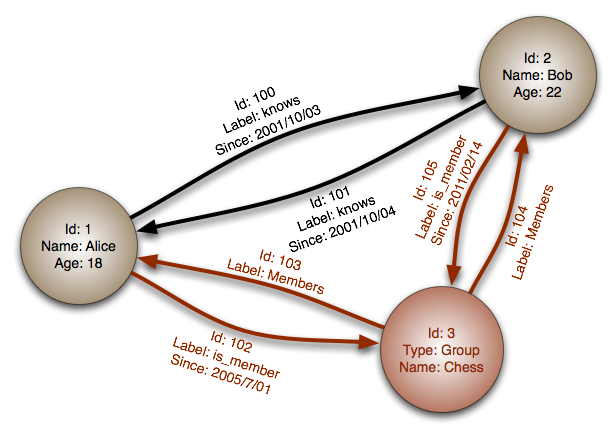
This means that when you query a graph database for all the cats with green eyes instead of iterating through every cat record (or in a more complex example multiple tables) too pull out records that contain the column eye_color and match green a graph database stores the edges directly so that the relationship green eyes is keyed directly to the nodes connected to it.
Instead of going into too much further detail I'll leave you with some future research on directed vs undirected graphs.
Note Taking and Organizing#

Ok, so what does any of this have to do with productivity or organizing. Well, I mentioned it at the top, but Logseq is a note taking and productivity app based on the idea of a knowledge graph and combines it with a bullet journal style (markdown powered) interface to create what they call your personal knowledge graph allowing you to link subjects, notes and individual todo items together into your own (github synced) web note taking app.
Ok, that sounds nice, but how do you use it
Well, if you already started editing your homepage you can spot their documentation on github but I'll go through some major takeaways:
Overview#
When you open logseq for the first time you will see either their demo page, or just a new Date named page (journal style) like this one (but with no content):
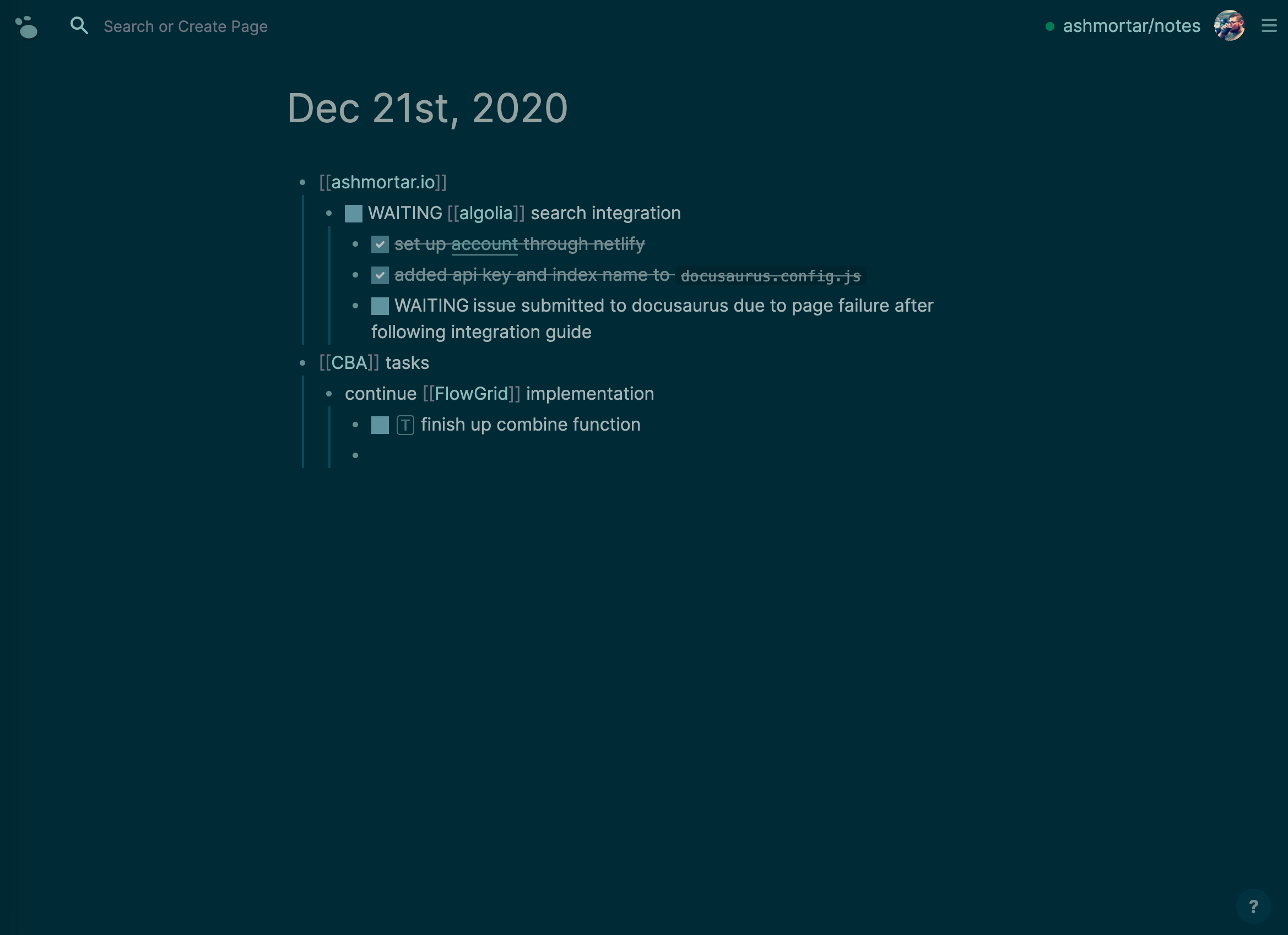
The core functionality lies around making nested TODO lists, but you will notice the [[<some name>]] syntax on some of my bullet items. This is how you create or reference another page in your knowledge graph. Click on that link (like CBA, my work project) and you'll be taken to that page:
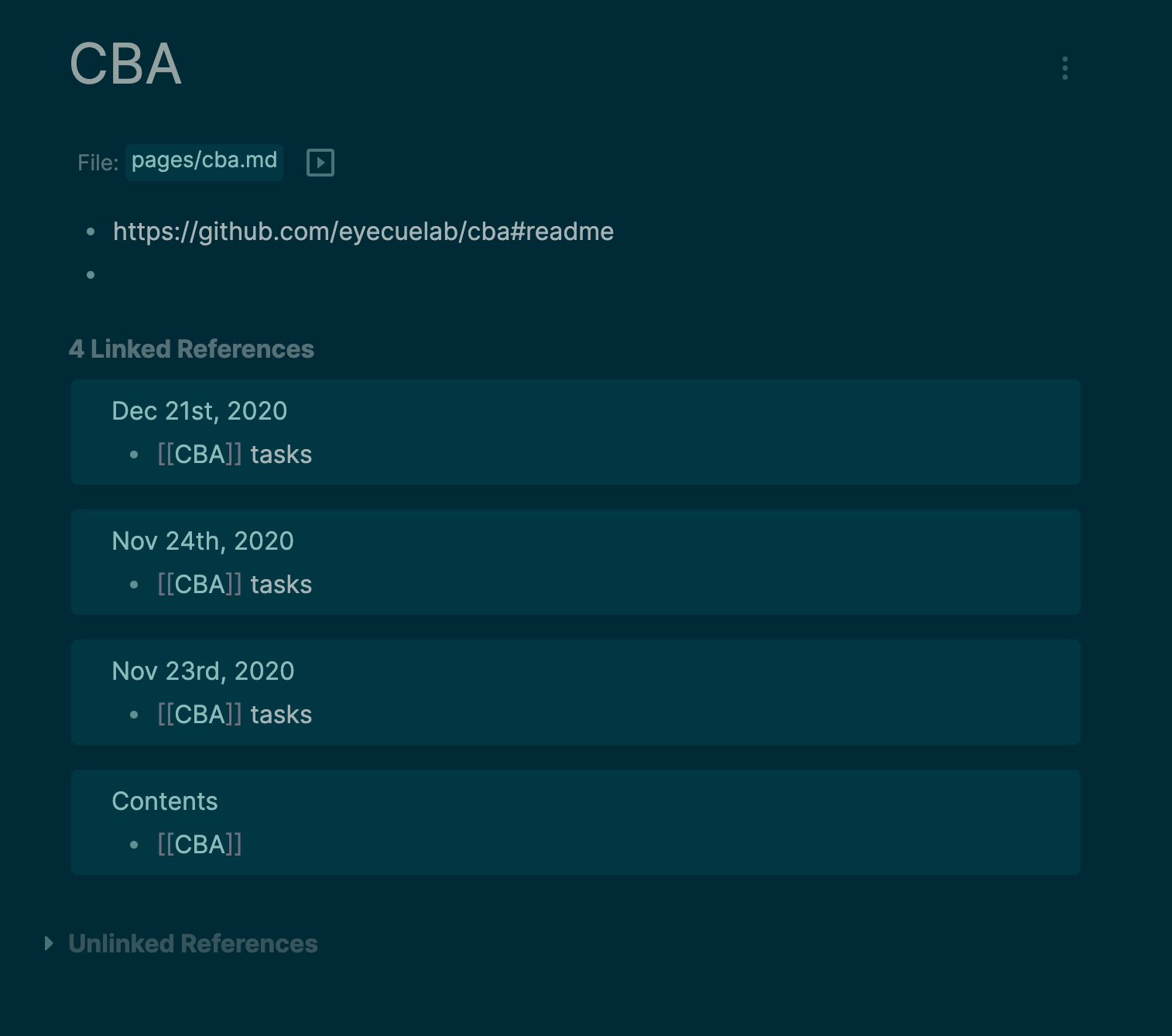
That contains both its own list as well as a linked references section that will show you all the other places in your knowledge graph that this page is referenced.
pretty cool, but what else?
I am so glad you asked. If you open up the hamburger menu on the top right of the page you can view:
Contents-- an editable/manageable table of contents for finding pages you use frequentlyRecents-- a history of your recently visited pagesPage Graph-- a visualization of this page (or node) and all its edges and connected nodes:
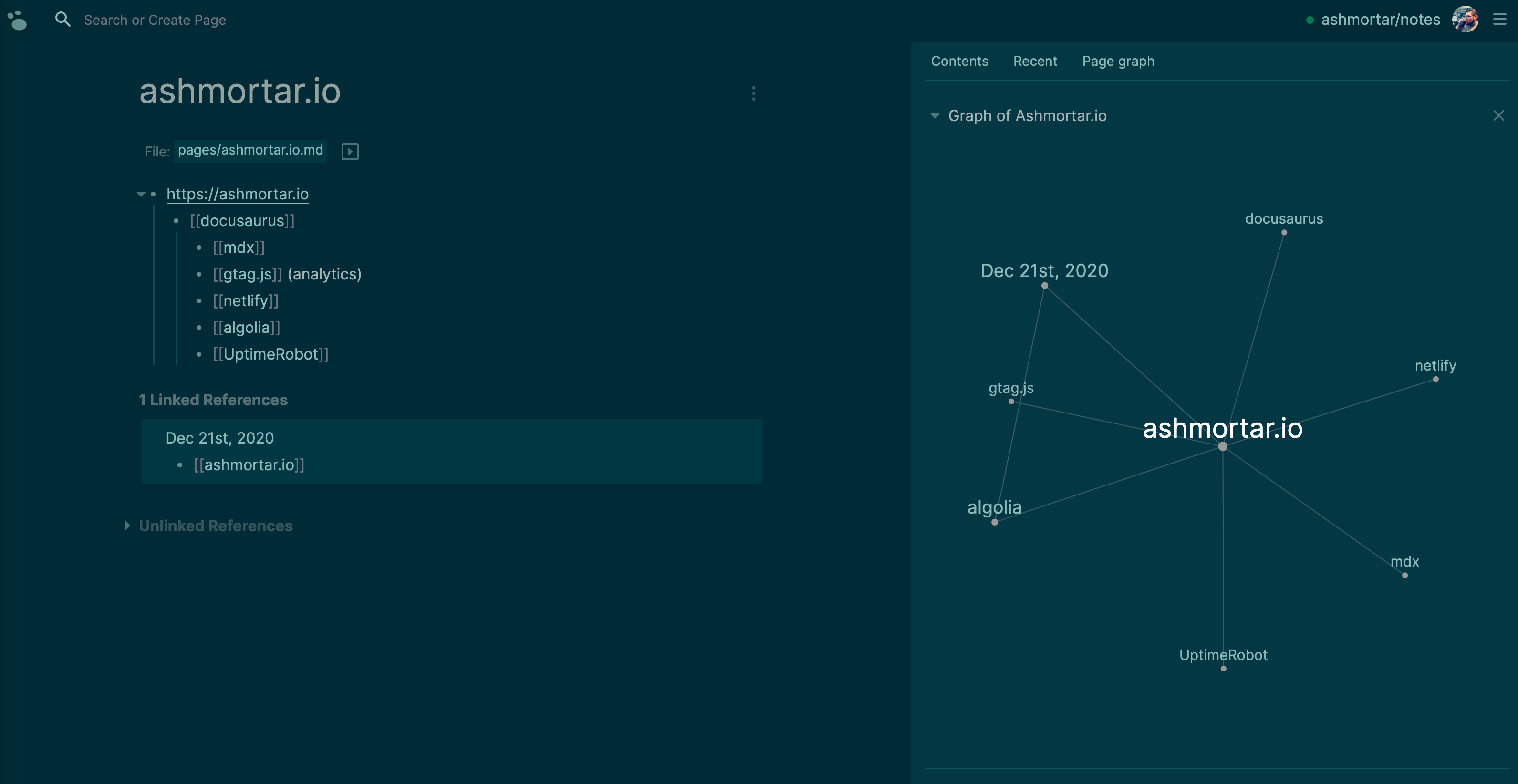
The reason this feature excites me is that it allows you (once you accrue and link content) to explore relationships between topics that you didn't see before or didn't realize existed. Not to mention that the tasks I did yesterday can now directly be linked to the tasks I need to do tomorrow. I can organize research by topic, throw a link into its category for future reading and mark it with /TODO to know that I didn't read it yet and then weeks or months later come back and see that resource, consume it and mark it /DONE.
Thanks for sticking through and I hope you give logseq a try. You can set up persistence across devices by setting up a dedicated github repository for the service to use as a backend or just operate on a single machine via local storage.